网络协议
网络请求工作流程
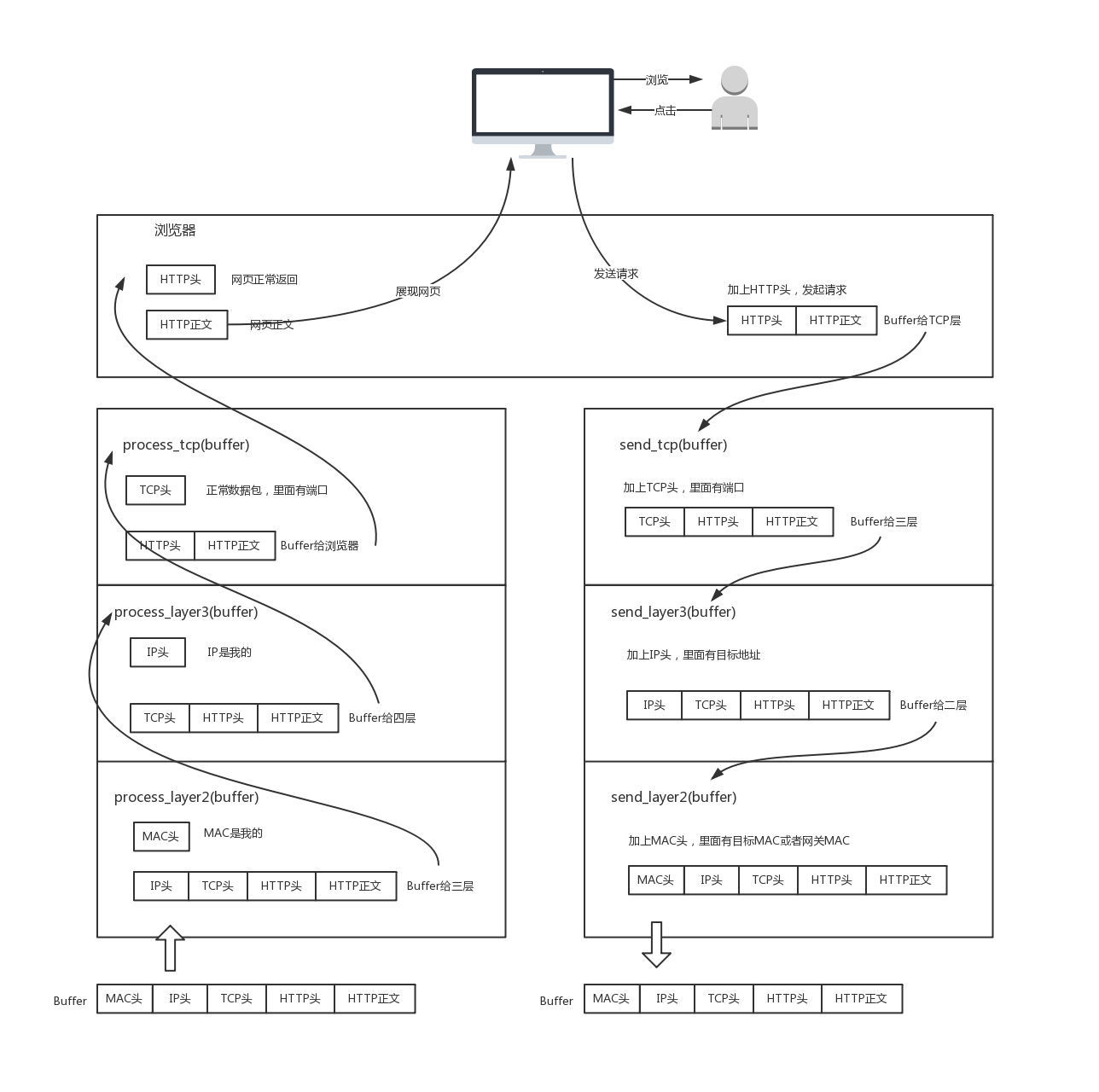
当一个网络包从一个网口经过时,可以把连接拿进来处理,有的网口配置了混杂模式,凡是经过的都处理。
当进入后调用process_layer2(buffer),当然这只是个名称,这个函数具体的工作内容是,从Buffer中摘掉二层的头,看看根据里面的内容做什么操作。
假设这个包的MAC地址和你的相符,那说明是给你的,调用`process_layer3(buffer)。这个时候Buffer里面往往就没有二层的头了,因为已经在上一个函数的处理过程中拿掉了,或者将开始的偏移量移动了一下。在这个函数里摘掉三层的头,看看是发给自己的,还是希望转发出去的。
如果IP地址不是自己的那就转发出去。根据IP头里面的标示,拿掉三层头,进行下一步处理。
如果是TCP的,则会调用process_tcp(buffer)。这时候Buffer里面没有三层的头了,需要查看四层的头,看这是一个发起还是一个应答,又或者是一个正常的数据包,然后分别由不同的逻辑处理。如果是发起或者应答,接下来可能要发送一个回复包;如果是一个正常的数据包,就需要交给上层了。
即交给应用去处理。在四层的头里面有端口号,不同的应用监听不同的端口号。如果发现浏览器正在监听这个端口,那发给浏览器就行了。
浏览器解析HTML,显示出页面。浏览器会捕获点击动作,并发起另一个HTTP请求,使用端口号将请求发送出去。
然后调用send_tcp(buffer)。Buffer里的内容就说HTTP请求的内容。这个函数里面加上TCP头,记录下源端口号。
然后调用send_layer3(buffer)。在新增加一个IP头,记录下源IP地址和目标IP地址。
然后调用send_layer2(buffer)。Buffer里面已经有了HTTP的头和内容、TCP的头,以及IP的头。这个函数里面要再增加一个MAC头,记录下源MAC地址,得到的就是本机MAC地址和目标MAC地址。不知道目标MAC地址的话可以通过协议获得。
只要是在网络上跑的包,都是完整的。可以有下层没上层,绝对不可能有上层没下层。所以对于TCP协议来说,三次握手也好,重试也好,只要想发出包,就要有IP层和MAC层,不然是发不出去的。
TCP&UDP
区别
一般认为,TCP是面向连接的,UDP是面向无连接的。
所谓的建立连接,是为了在客户端和服务端直接维护连接,建立一定的数据结构维护双方交互状态,用这样的数据结构来保证所谓的面向连接的状态。
TCP提供可靠交互。通过TCP发送的包,无差错、不丢失、不重复、并且按顺序到达。IP包是没有任何可靠性保障的,一旦发出去就只能随它去。UDP继承了IP包的特性,不保证无差错,不保证按顺序到达。
TCP是面向字节流的。发送的时候是一个流,没头没尾,因为TCP已经维护了一个状态。UDP是基于数据包的,一个包一个包的发,一个一个的接。
TCP可以拥有阻塞控制。可以意识到包丢失或者网络环境不好,可以根据情况调整自身的行为,发送快慢。UDP不会,应用让发就发。
TCP是一个有状态的服务,里面记录了发送了没有,接到了没有,发到哪了,接到哪里了,错一点都不行。UDP发出去就是发出去了,不会记录其他信息。
UDP
UDP三大特点:
- 沟通简单:不需要大量数据结构、处理逻辑、包头字段等。并且默认网络是良好的,包是不会丢失的。
- 随意:它不会建立连接,只是监听端口,谁都可以传给它数据,它也可以给任何人传数据,甚至同时发给多个人。
- 耿直:不会根据网络情况控制发包,无论是否拥堵,照发无误。
UDP三大使用场景:
- 需要资源少,网络情况比较好的内网,或者是对丢包不敏感的应用。
- 不需要一对一沟通,建立连接,而是可以广播的应用。
- 需要处理速度快,延迟低,可以容忍适度丢包,即使是在网络拥堵的时候也勇往直前的时候。
UDP使用案例:
- 流媒体协议:对于直播来讲,老的视频帧已经没有用了,只需要再继续传新的就可以了,对于实时性比较看重,宁可丢帧也尽量不要卡顿。TCP协议会在网络不好时候降低传输速率,只能是越来越卡。所以很多直播应用都基于UDP实现了自己的视频传输协议。
- 实时游戏:游戏对实时性要求比较严格,可以采用自定义的可靠UDP协议,自定义重传策略,能够把丢包产生的延迟降到最低,尽量减少网络问题对游戏的影响。
- IoT物联网:物联网领域终端资源少,一般都是小型嵌入式系统,维护TCP成本太大;而且一般对实时性要求也比较严格。
- 移动通信领域:在4G网络里,移动流量上网的数据传输协议GTP-U就是基于UDP的。移动网络协议非常复杂,不需要TCP的其他机制。
TCP
TCP是靠谱的协议,从IP层面来讲,如果网络实在差,作为IP的上一层TCP也无能为力,唯一能做的就是通过算法各种重传;对于TCP来讲,IP层你丢不丢包我不管,但是在我的层面尽量保持可靠。
TCP三次握手
也即,"请求->应答->应答之应答"。
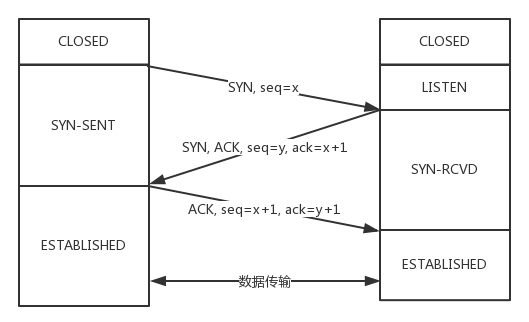
建立在假设网络通路非常不可靠的基础是,A发起一个连接,当第一个链接杳无音信的时候,有很多种可能性,包丢了、超时了、绕路了、B没有响应等。
当B应答请求的时候也面临同样的问题,所以至少要等到A再次回答的时候才能建立连接。
三次握手除了建立连接外,主要还为了沟通一件事情,TCP包的序号的问题。
A要告诉B,我这面发起的包的序号是多少,B也同样要告诉A。为什么不每次都从1开始呢?因为怕出现冲突。
比如A连接上B后,发送了1,2,3三个包,但是发送3的时候断线了,过后当A重新连接上B之后当然不能发送第四个包继续以1为序号发送。
因此,每个连接都要有不同的序号。这个序号可以看成是随着时间变化的,可以看成一个32位的计数器,每4ms加一,如果要重复序号需要4个多小时。
tcp四次挥手
也即,"A:请求下线->B:应答下线->B:完成工作并下线->A:收到下线"。
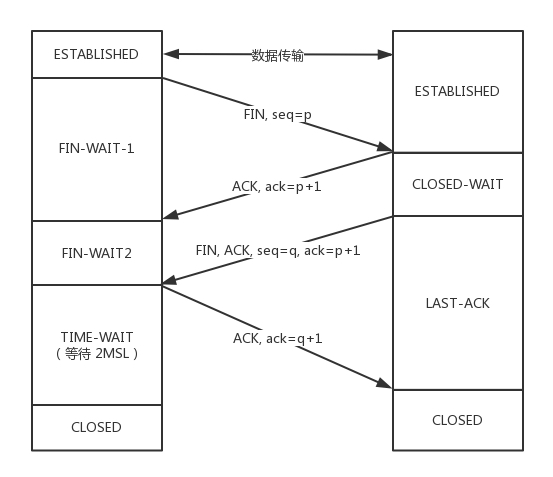
当A发送下线请求的时候,只是A要下线,并且不再发送数据,但是此时B有可能还没有做完自己的事情,还是可以发送数据的,A等B做完工作并主动关闭。
这是正常情况下的关闭连接,但是其中后两步可能会出现问题,比如一方先跑路了,这时就可能出现另一方无限等待的可能,需要设置超时时间来解决。
TCP状态机
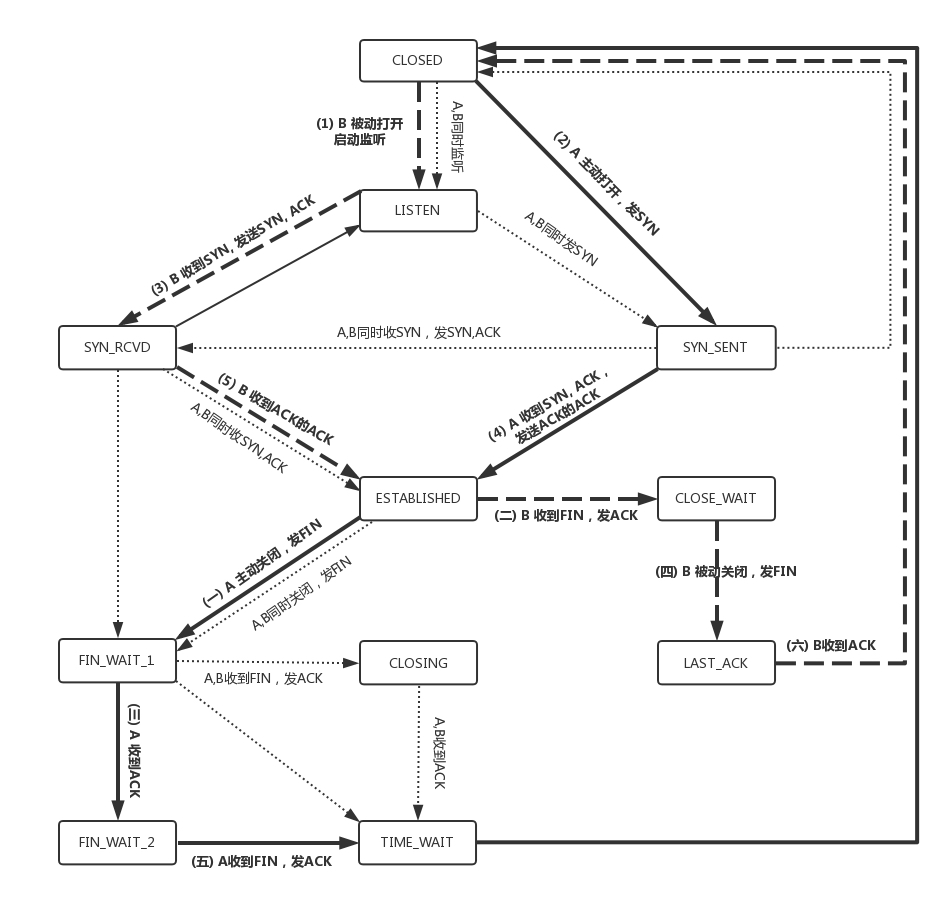
TCP协议实现
为了保证顺序性,每个包都有一个ID,在建立连接的时候会商定起始ID是什么,然后会按照顺序发送。为了防止丢失,发送的包都要应答,但是不是每个包都应答一次,而是会应答某个ID之前的所有包,这种模式成为累计应答。
为了记录所有的发送包和接收包,TCP需要发送端和接收端分别缓存这些记录。
发送端记录分为四种:
- 第一部分:发送了且已经确认了的。
- 第二部分:发送了但是尚未确认的。
- 第三部分:没有发送,但是等待发送。
- 第四部分:没有发送,且暂时不准备发送的。
接收端记录分为三种:
- 第一部分:接收并且确认了的。
- 第二部分:还没接收,但是马上就能接收到的。
- 第三部分:还没接收,但是没法接收的。
确认与重发机制
一种方法是超时重试,对每一个发送了,但是没有收到回复的包都设有一个定时器,超时重试。这个超时时间需要由自适应重传算法根据网络状况变动取样算出。
拥塞控制
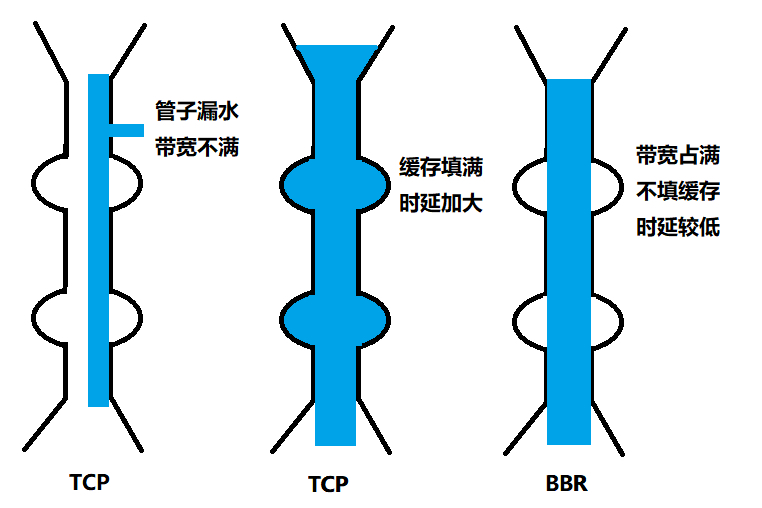
即网络拥塞问题,发送方如何判断网络是否满呢?对于TCP来讲,网络对他来说就是一个黑盒。TCP发送包常被比喻为往一个水管里注水,而TCP的拥塞控制就是,在不拥堵,不丢包的情况下,尽量发挥带宽。
如果我们设置发送窗口,使得发送但是未确认的包正好等于通道容量,就能装满整个管道。
TCP的拥塞控制就是用来避免包丢失和超时重传。一旦出现这两个问题就说明速度太快了。
这个问题有点像往瓶子里灌水,一开始要慢慢的倒,之后加速,也叫慢启动。
但是仍然有两个问题:
第一个是,丢包不代表管道满了,有可能本来就是管子漏。这个时候认为管道满了就不对。
第二个是,TCP的中间缓存设备都填满了,才发生丢包,降低速度,这事已经晚了,应该在管道满了的时候就降低速率,而不是等缓存满了才降低。
为了优化这两个问题,后来有了TCP BBR拥塞算法。它企图找到一个平衡点,就是不断加速发送,将管道填满,但是不要填满中间设备的缓存,因为这样会增加延迟,在这个平衡点可以达到很高的带宽有和低延迟的平衡。
HTTP协议
当请求一个URL的时候,浏览器会将域名发送给DNS服务器,并获取到IP地址。HTTP协议是基于TCP协议的,所以接下来先建立TCP连接,三次握手。并且在可以在多次请求中复用TCP连接。
HTTP请求
请求的格式:
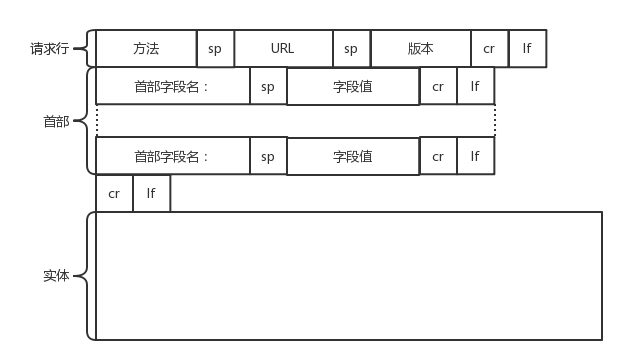
HTTP的报文分三部分,请求行,首部,正文实体。
- 请求行:方法就是常用的GET/POST等。
- 首部字段:一般是key/value,通过冒号分割。例如Accept-Charset表示客户端可以接受的字符。
已经拼凑好了发送格式,接下来浏览器就会把它交给传输层。
HTTP请求发送
HTTP是基于TCP的,所以使用面向连接的方式发送请求,通过stream二进制流方式传给对方。当到达TCP层时,会把二进制流转换为报文段发送给服务器。
TCP层没法送一个报文的时候,都需要加上自己的地址和目标地址,将这两个信息放到IP头里,交给IP层进行传输。
IP层需要查看自己和目标地址是不是在同一个局域网,如果是,就发送ARP请求获取目标地址的MAC地址,将源MAC和目标MAC放入MAC头发送出去即可。如果不是在同一个局域网,和刚才的步骤一样,只不过是请求网关的MAC并发送给网关。
网关收到包发现MAC符合,取出目标IP,根据路由协议找到下一目标路由器,并获取路由器的MAC地址,然后发出去。
经过多次路由,最终达到了目标局域网。在局域网内获取目标MAC地址并发出去。
目标机器发现MAC符合,就将包收进来;发现IP符合,根据IP中的协议项,知道了上层是TCP协议,于是解析TCP头,里面有序号,看看这一系列包是不是我要的,如果是就放入缓存中并返回一个回复ACK,如果不是就丢弃。
TCP头里面还有端口号,HTTP的服务器正在监听这个端口号。于是目标机器将包发送给服务器,服务器看到是要请求一个网页,于是把这个网页发给客户端。
HTTP返回
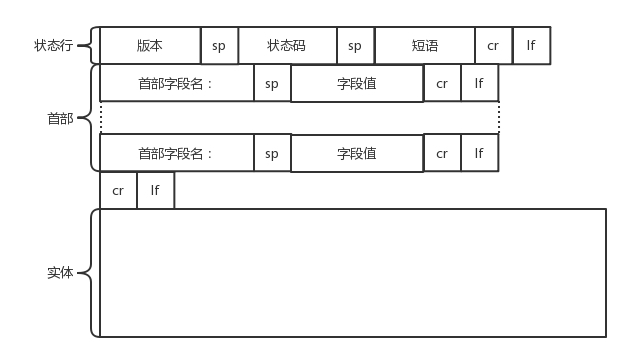
构建好了返回的HTTP报文,接下来就是把报文发出去。还是交给socket发送,还是交给TCP层,让TCP将返回的HTML也分成一个个小段,并保证每个段都可以到达。
返回的过程和发送过程一样,虽然两次不一定走相同的路径,但是逻辑一样,并且到达客户端。
HTTP 2.0
HTTP2.0对HTTP头进行一定压缩,将原来每次都要携带的key/value在两端建立索引表,相同的头只发送索引即可。
并且将一个TCP连接中,切分成多个流,每个流都有自己的ID。
还将所有的传输信息分割为更小的消息和帧,并对他们采用二进制格式编码。
通过这两种机制,HTTP2.0的客户端可以将多个请求分到不同的流中,然后将请求拆分成帧,进行二进制传输。帧可以打乱顺序,然后根据标示重新组装,并且可以根据优先级决定先处理哪个流的数据。
QUIC协议
QUIC协议通过基于UDP自定义类似TCP的连接、重试、多路复用、流量控制技术进一步提升性能。
HTTPS协议
HTTPS工作模式
非对称加密的公匙私匙用来传递对称加密的密匙,真正双方大数据量的通信是通过对称加密进行的。
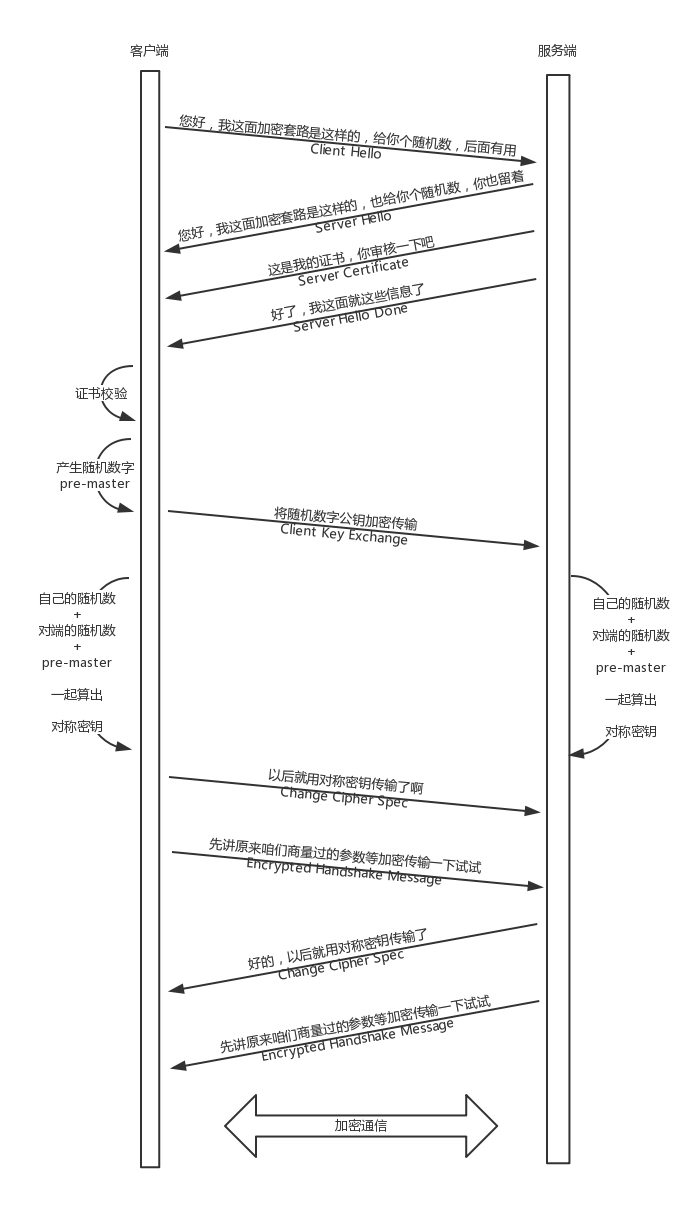
过程除了加密解密之外,其他过程和HTTP是一样的。
可能会遇到重放和篡改问题。有了加密,黑客截获了包也打不开,但是可以重发N次。这个解决方案往往是通过Timestamp和Nonce随机数联合起来,做一个不可逆的签名来保证。
内容主要来自极客时间