Redis深度历险
Redis基础
基础数据结构
- string
Redis所有的数据结构都是以唯一的key字符串作为名称,然后通过key来获取对应的value,不同数据类型的差异就在于value结构不同。
是动态可修改的字符串,当长度小于1m时扩容为双倍,当超过1m时每次只扩容1m,最大长度为512m。
- list
list是链表结构。当列表弹出最后一个元素后,该数据结构自动删除,内存被回收。
列表结构常用来做异步队列使用,将需要延后处理的任务结构体序列化成字符串塞进Redis的列表,另一个线程从这个列表中轮询数据进行处理。
Redis地城存储的不是一个简单的linkedlist,而是称为quicklist结构。
在列表元素少的情况下使用一块连续的内存存储,称为ziplist,并将链表和ziplist组合成了quicklist,即将多个ziplist使用双向指针串起来使用。
- hash
类似java的hashmap,第一维hash的数组位置碰撞时使用链表串起来。
Redis的字典值只能是字符串。为了提高性能不阻塞服务,采用了渐进式rehash策略,即保留新旧两个hash结构,循序渐进的将就hash内容迁移到新hash结构中。
- set
内部实现相当于一个特殊字典,所有value都是null。
- zset
类似于Java的sortedset和hashmap的结合体。set保证了内部value的唯一性,并可以给每个value一个score,代表权重。内部实现是跳表。
容器型数据结构通用规则
指list/set.hash/zset这四种容器数据结构,有两条通用规则
- create if not exists
- drop if no elements
分布式锁
分布式锁
锁一般使用setnx(set if not exists)指令,只允许一个客户端进入,先来先用,用完调用del指令释放。但是如果执行中出现异常,会导致del指令没有被调用而陷入死锁。所以通常加一个过期时间,超时自动释放。
Redis2.8中加入了set指令,使得setnx和expire指令可以一起执行组合成原子指令。
延迟队列
Redis可以轻松搞定那些只有一组消费者的消息队列。
异步消息队列
list数据结构常用来作为异步消息队列,使用rpush/lpush操作入队列,使用lpop和rpop来出队列。
如果队列空了,客户端会陷入pop死循环,通常使用sleep解决,睡1s。但是会显著增加延迟,更好的解决方案是使用blpop/brpop,b表示blocking。
位图
位图不是特殊的数据结构,知识byte数组。一般用于存储bool类型数据,可以节省大量储存空间。比如签到数据。
HyperLogLog
HyperLogLog数据结构用来提供不精确的去重技术方案,标注误差0.81%,可以满足UV统计需求。
但是这个数据结构要占用12k的存储空间,所以它不适合统计单个用户相关的数据。
HyperLogLog实现原理
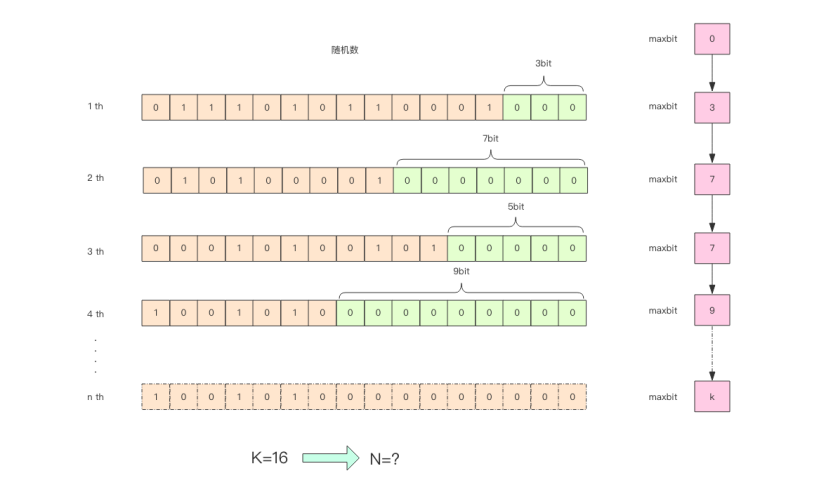
给定一系列的随机证书,记录下低位连续零位的最大长度k,通过k值可以估算出随机数的数量。
pf内存占用为什么是12k
在Redis的HyperLogLog实现中用到了16384个桶,即2^14,每个桶maxbits需要6个bits来存储,最大可以表示maxbits=63,总占用内存就是2^14*6/8=12k字节。
布隆过滤器
布隆过滤器可以理解为一个不绝对精确的set结构,当你使用它的contains方法判断某个对象是否存在时,它可能会误判。
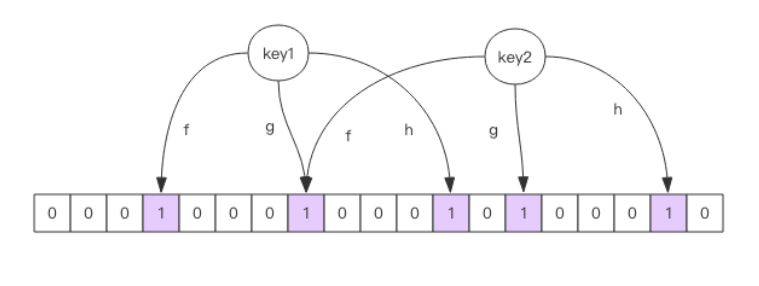
每个布隆过滤器对应到Redis的数据结构里面就是一个大型的位数组和几个不一样的无偏hash函数,即能把元素的hash算得比较均匀。
向布隆过滤器中添加key时,会使用多个hash函数对key进行hash算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个hash函数都会算出一个位置,然后再把这几个位置都设置为1就完成了add操作。
查询key是否存在时,只需要把hash的几个位置算出来,看看这几个位置是否都为1,只要有一个0就说明不存在。
GeoHash
可以利用Redis的地理位置GEO模块实现摩拜单车附近的Mobike类似的功能。
用数据库来计算附近的人
地图元素的位置数据使用二维的维度表示,经度(-180,180],纬度范围(-90,90]。
当两个元素距离不是很远的时候可以直接使用勾股定理算得距离。
但是如果要计算[附近的人],给定一个元素的坐标,计算附近的其他元素,你不可能通过遍历来计算所有的元素和目标元素的距离然后排序。一般的方法都是通过矩形区域来限定元素数量,然后对区域内元素进行全量距离计算并排序。
为了满足高性能矩形区域算法,数据表需要在经纬度坐标加上双向符合索引(x,y)。但是在高并发场合这并不是一个好办法。
GeoHash算法
GeoHash算法将二维的经纬度映射到一维的整数,所有元素都挂载到一条线,距离靠近的二维坐标,映射到一维后的点之间的距离也会更接近,只需要在一维的线上获取附近的点就行。
映射算法:
把地球看成一个二维平面,划分成一些列正方形方格,将地图元素放置于唯一的方格中,方格越小越精确。然后对这些方格进行整数编码,越靠近的方格编码越接近。一个编码方案就是切蛋糕法。比如用两刀均匀切分成四个小正方形,这四个小正方形可以分别标记为00,01,10,11四个二进制整数。然后对每一个小正方形继续二刀法切割,这时候更小的正方形就可以用4bit的二进制数表示,继续切下去,二进制数越来越长,精度也越来越高。
GeoHash会继续对整数做一次base32编码变成字符串。在Redis中,经纬度使用52位的整数进行编码,放进zset里面,通过zset的score排序就可以得到坐标附近的其他元素,通过将score还原成坐标值就可以得到元素的原始坐标。
Scan
scan相比keys具有以下特点:
- 复杂度虽然也是O(n),但是它是通过游标分步进行的,不会阻塞线程
- 提供limit参数,可以控制每次返回结果条数
- 也提供模式匹配功能
- 服务器不需要为游标保存状态,游标唯一的状态就是scan返回给客户端的游标整数
- 返回的结果可能有重复,需要客户端去重
- 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的
- 单词返回的结果是空不意味着遍历结束,而要看返回的游标值是否为零
字典结构
scan指令返回的游标就是第一维数组的位置索引,将这个位置索引称为槽(slot)。如果不考虑字典的扩容缩绒,直接按数组下标挨个遍历就行了。limit参数就表示要遍历的槽位数,之所以返回的结果可能多可能少,是因为不是所有的槽位上都会挂载链表,有些槽可能是空的,还有些槽上挂接的链表上的元素可能会有多个。每一次遍历都会将limit数量的槽位上挂接的所有链表元素进行模式匹配过滤后,一次性返回给客户端。
线程IO模型
Redis是单线程程序!
速度快是因为所有的数据都在内存中,所有的运算都是内存级别的运算。
非阻塞IO
当调用套接字读写方法时,默认是阻塞的,比如read方法要传递进去一个参数n,表示读取这么多字节后在返回,如果没有读够线程就会卡在哪里,直到新的数据来或者链接关闭了,read方法才可以返回,线程才能继续处理。而write方法一般来说不会阻塞,除非内核为套接字分配的写缓冲区已经满了,write方法就会阻塞,直到缓存区中有空闲空间挪出来。
通信协议
Redis的作者认为数据库系统的瓶颈一般不在于网络流量,而是数据库自身内部逻辑处理上。所以即使Redis使用了浪费流量的文本协议,依然可以取得极高的访问性能。Redis将所有的数据都放在内存,用一个单线程对外提供服务,单个节点在跑慢一个CPU核心的情况下达到了10w/s的超高QPS。
-
RESP(Redis Serialization Protocol):是一种直观的文本协议,优势在于实现异常简单,解析性能极好。
- 客户端->服务器:只有一种格式,多行字符串数组
- 服务器->客户端:响应信息是5种基本类型的组合
持久化
用来保证突然宕机时内存中数据丢失问题。
有两种机制,一种是快照,一种是AOF日志。
- 快照:一次全量备份,内存数据的二进制序列化形式,存储紧凑。使用COW(Copy On Write)机制来实现快照持久化。
- AOF日志:连续的增量备份,记录的是内存数据修改的指令记录文本。长期运行会无比庞大,需要定期进行AOF重写。可以通过对一个空的Redis实例顺序执行所有的指令,即重放,来回复Redis当前实例内的内存数据结构状态。
管道
实际上Redis管道本身不是Redis服务器直接提供的技术,这个技术本质上是由客户端提供的,跟服务器没有什么直接关系。
Redis的消息交互
当我们使用客户端对Redis进行一次操作时,客户端将请求传送给服务器,服务器处理完后,在将相应回复给客户端,这需要花费一个网络数据包来回的时间。
如果连续执行多条指令,那么就会花费多个网络包来回的时间。
对于客户端代码层面,客户端经历了写-读-写-读四个操作完成了两条指令。
如果我们调整读写顺序,变成写-写-读-读,同样可以完成指令,但是只会花费一次网络来回。
这就是管道操作的本质,服务器根本没有任何区别对待。
事务
Redis的事务使用非常简单,不同于关系数据库,无需理解那么多复杂的事务模型就可以直接使用。
- multi:指示事务开始
- exec:事务执行
- discard:事务丢弃
所有指令在exec之前不执行,而是缓存在服务器的一个事务队列中,服务器一旦收到exec指令,才开始执行整个事务队列,执行完毕后返回所有指令的运行结果。由于Redis的单线程特性,指令自带原子性。
PubSub
Redis的消息队列不支持消息的多播机制。
消息多播
消息多播允许生产者生产一次消息,中间件负责将消息复制到多个消息队列,每个消息队列由相应的消费组进行消费。它是分布式系统常用的一种解耦方式,用于将多个消费组的逻辑进行拆分。支持了消息多播,多个消费组的逻辑就可以放到不同的子系统中。
如果是普通的消息队列,就得将多个不同的消费组逻辑串接起来放在一个子系统中进行连续消费。
PubSub
Redis单独使用了一个模块来支持消息多播,即PubSub,PublisherSubscriber,发布者订阅模型。
客户端发起订阅命令后,Redis会立即给予一个反馈消息通知订阅成功。因为有网络传输延迟,在subscribe命令发出后,需要休眠一会,再通过get_message才能拿到反馈消息。客户端接下来执行发布命令,发布了一条消息。同样因为延迟,在publish命令发出后,需要休眠一会才能拿到发布的消息。如果没有消息会返回空,所以它不是阻塞的。
小对象压缩
Redis作者为了优化数据结构的内存占用,也苦心孤诣增加了很多优化点,即使是以牺牲代码可读性为代价,但是这是非常值得的。
Redis如果使用32bit进行编译,内部所有数据结构所使用的指针空间占用会减少一半,如果使用内存不超过4G,可以考虑用32bit进行编译。
小对象压缩存储 ziplist
如果Redis内部管理的集合数据结构很小,它会使用紧凑存储形式压缩存储。这就好比HashMap本来是二维结构,但是如果内部元素比较少,使用二维结构反而浪费空间,还不如使用一维数组进行存储。
内存回收机制
Redis并不总是可以将空闲内存立即归还给操作系统
如果当前Redis内存有10G,当你删除了1GB的key后,再去观察内存,你会发现内存变化不会太大,原因是操作系统回收内存是以页为单位,如果这个页上只要有一个key还在使用,那么它就不能被回收。Redis虽然删除了1GB的key,但是这些key分散到了很多页面中,每个页面都还有其他key存在,这就导致了内存不会立即被回收。
不过如果你执行flushdb,然后在观察内存会发现内存确实被回收了。原因是所有的key都干掉了,大部分之前使用的页面都完全干净了,会立即被操作系统回收。
Redis虽然无法保证立即回收已经删除的key内存,但是它会重用那些尚未回收的空闲内存。就好比电影院虽然人走了,但是作为还在,下一波观众来了直接坐就行;而操作系统回收内存就好比把座位都给搬走了。
内存分配算法
Redis为了保持自身结构的简单性,将内存分配细节用第三方库实现。目前Redis默认使用jemalloc库。
主从同步
有了主从,当master挂掉的时候,运维让从库过来接管,服务就可以继续。
CAP原理
- C - Consistent ,一致性
- A - Availability , 可用性
- P - Partition tolerance , 分区容忍性
即,网络分区(网络断开)发生时,一致性和可用性两难全。
最终一致
Redis的主从数据是异步同步的,所以分布式的Redis系统不满足一致性要求。当客户端在Redis的主节点修改了数据后,立即返回,即使在主从网络断开的情况下,主节点依旧可以正常对外提供修改服务,所以满足可用性。
Redis保证最终一致性,当断开的网络恢复后,从节点会努力追赶主节点,从而保持一致。
增量同步
Redis同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地内存buffer中,然后异步将buffer中的指令同步到从节点。
但是内存buffer有限,容量满了后会覆盖前面的内容。那么如果断线时间太长可能会导致没同步的指令已经被覆盖,所以需要用到更复杂的同步机制–快照同步。
快照同步
首先在主库上进行一次bgsave将当期内存的数据全部快照到磁盘文件中,然后再将快照文件的内容全部传送到从节点。从节点将快照文件接受完毕后,立即执行一次全量加载,加载之前先要将当前内存的数据清空。加载完毕后通知主节点继续增量同步。