Docker原理
docker容器
容器其实是一种沙盒技术。沙盒就是能够像一个集装箱一,把应用"装"起来,这样应用与应用之间就有了边界且互不影响;并且装进集装箱可以方便的搬来搬去,也即PaaS的理想状态.
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而创造出一个"边界"。
对于Docker容器来说,Cgroups技术用来制造约束,Namespace技术用来修改进程视图。
下面通过例子来说明这两个概念
首先需要linux环境,并且安装好了docker
$ docker run -it busybox /bin/sh
/ #
-it参数告诉了Docker项目在启动容器后,分配一个文本输入/输出环境,也就是TTY,跟容器标准输入相关联,从而和容器进行交互。/bin/sh就是要在docker容器里运行的程序。
此时我们在容器里执行ps指令:
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
10 root 0:00 ps
只有两个进程在运行,且PID为1的进程就是/bin/sh,这时,前面执行的/bin/sh,以及刚刚执行的ps已经被Docker隔离在了一个跟宿主机完全不同的环境中。
Namespace机制
每当在宿主机上运行一个程序,系统就会给程序分配一个进程编号PID,先运行的PID越小。而现在要通过Docker把/bin/sh程序运行在一个容器中,Docker就会使用一个"障眼法",让它看不到在它之前运行的程序,并以为自己就是第一个运行的程序。可实际上,他们在宿主机的操作系统里,还是原来的PID。
虚拟机与容器
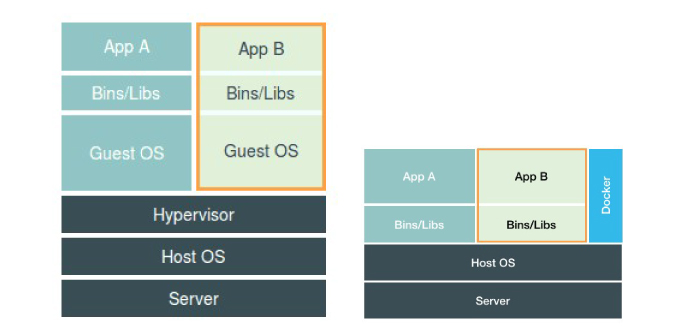
虚拟机通过Hypervisor虚拟化硬件,模拟出一个操作系统各种硬件,然后在这些虚拟硬件上安装一个新的操作系统。这样用户进程就可以运行在虚拟机中,能看到的也只有虚拟机系统中的文件和目录,也起到了隔离的作用。
但是容器和虚拟机之间还有区别的。在使用Docker的时候,没有一个真正的"Docker容器"运行在宿主机里。 Docker帮助用户启动的还是原来的应用程序,只不过在创建进程的时候加上了各种各样的Namespace参数。
容器优势
容器化后的应用,依然还是一个宿主机上的普通进程,这就减少了虚拟化带来的性能损耗,并且使用Namespace作为隔离手段的容器并不需要单独的操作系统,容器额外的资源占用可以忽略不计。
"敏捷"和"高性能"是容器对于虚拟机最大的优势,也是它能在PaaS这种更细粒度的资源管理平台上大行其道的重要原因。
容器劣势
隔离的不彻底 : 多个容器之间使用的还是同一个宿主机的操作系统内核。
比如你无法在Windows宿主机上运行Linux容器,或者在低版本的Linux上运行高版本的Linxu容器。
Linux内核中有很多资源和对象是不能被Namespace化的,比如时间。 所以生产环境中没人敢把运行在物理机上的Linux容器直接暴露到公网上。也有基于虚拟化或者独立内核技术的容器实现,可以在隔离与性能之间做出平衡。
Cgroups限制
Linux Control Group 。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括CPU、内存、磁盘、网络等。
在Linux中,Cgroups给用户暴露出来的操作接口是文件系统,它以文件和目录的方式组织在操作系统的/sys/fs/cgroup路径下。在Ubuntu中通过以下命令展示出来:
mount -t cgroup
cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
...
配置Cgroups
root@ubuntu:~# cd /sys/fs/cgroup/cpu
root@ubuntu:/sys/fs/cgroup/cpu# mkdir container
root@ubuntu:/sys/fs/cgroup/cpu# ls container/
cgroup.clone_children cpuacct.stat cpuacct.usage_all cpuacct.usage_percpu_sys cpuacct.usage_sys cpu.cfs_period_us cpu.shares notify_on_release
cgroup.procs cpuacct.usage cpuacct.usage_percpu cpuacct.usage_percpu_user cpuacct.usage_user cpu.cfs_quota_us cpu.stat tasks
这个目录称为"控制组"。目录下自动生成该子系统对应的资源限制文件。
接下来执行一个死循环并查看占用:
$ while : ; do : ; done &
[1] 21900
查看cpu占用到100%
$ top
查看container控制组内还没有任何限制(即-1),周期默认100ms(100000us)
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
接下来通过修改文件来设置限制,向cfs_quota文件写入20ms(20000us):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
意思是在每100ms的时间里,被该控制组限制的进程智能使用20ms的CPU时间,也就是说这个进程只能使用到20%的CPU带宽。
现在并没有生效,还需要把被限制的进程PID写入container组里的tasks文件:
$ echo 21900 > /sys/fs/cgroup/cpu/container/tasks
Linux Cgroups的设计还是比较易用的,简单理解就是一个子系统目录加上一组资源限制文件的组合。 对于Docker等容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即目录),然后在启动容器进程之后,把这个进程的PID添加到对应控制组的tasks文件中就可以了。
可以通过docker run的参数直接指定:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
然后在容器外的终端执行:
cat /sys/fs/cgroup/cpu/docker/容器id/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/容器id/cpu.cfs_quota_us
20000
容器只是一个特殊进程
一个正在运行的Docker容器,其实就是一个启用了多个Linux Namespace的应用进程,而这个进程能够使用的资源量,受Cgroups配置限制。
容器是一个"单进程"模型。
由于一个容器的本质就是一个进程,用户的应用进程实际上就是容器里的PID=1的进程,也是其他后续创建的所有进程的父进程。这就意味着,在一个容器中,你没有办法同时运行两个不同的应用,除非你能事先找到一个公共的PID=1的程序来充当两个不同应用的父进程,这就是为什么很多人都用systemd或者supervisord这样的软件来替代应用本身作为容器的启动进程。
文件系统的namespace - Mount Namespace
实际需求中往往希望,每当创建一个新容器的时候,容器进程看到的文件系统都是一个独立的隔离环境,而不是继承自宿主机的文件系统。
假设有一个$HOME/test目录,想要把它作为一个/bin/bash进程的根目录。
创建test目录和几个文件夹
$ mkdir -p $HOME/test
$ mkdir -p $HOME/test/{bin,lib64,lib}
$ cd $T
把bash命令拷贝到test目录对应的bin路径下
$ cp -v /bin/{bash,ls} $HOME/test/bin
把bash命令需要的所有so文件,也拷贝到test目录对应的lib路径下
$ T=$HOME/test
$ list="$(ldd /bin/ls | egrep -o '/lib.*\.[0-9]')"
$ for i in $list; do cp -v "$i" "${T}${i}"; done
最后执行chroot命令,告诉系统使用$HOME/test目录作为/bin/bash进程的根目录
$ chroot $HOME/test /bin/bash
这是执行ls /就会返回$HOME/test目录下的内容,而不是宿主机的。
而且对于被chroot的进程来说,它并不会感受到自己的根目录已经被修改了。
这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的"容器镜像"。也叫rootfs(根文件系统)。
对于Docker项目来说,最核心的原理就是为待创建的用户进程执行:
- 启用Linux Namespace配置
- 设置指定的Cgroups参数
- 切换进程的根目录(change root)
需要注意的是,rootfs只是一个操作系统包含的文件、配置和目录,并不包括操作系统内核。在Linux操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本内核镜像。
这就意味着,如果你的应用程序需要配置内核参数、加载额外的内核模块,以及跟内核进行直接的交互,你就需要注意了:这些操作和依赖的对象,都是宿主机操作系统的内核,它对于该机器上的所有容器来说都是一个"全局变量",牵一发而动全身。
docker volume
容器技术使用了rootfs和Mount Namespace,构建出了一个同宿主机完全隔离开的文件系统,那么如何让宿主机获取到容器里新建的文件?容器怎么访问宿主机的文件和目录?
Volume机制,允许你讲宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改。
以下是两种Volume声明方式,把宿主机目录挂载进容器的/test目录:
$ docker run -v /test ...
$ docker run -v /home:/test ...
第一种情况,没有显示的声明宿主机目录,docker会在宿主机创建一个临时目录/var/lib/docker/volumes/[VOLUME_ID]/_data,并把它怪哉到容器/test目录上。
第二种情况,直接把宿主机的/home目录挂载到容器的/test目录。
这里使用到的挂载技术,就是linux的绑定挂载(bind mount)机制。作用就是允许你将一个目录或者文件,而不是整个设备挂载到一个指定的目录上。这时你在该挂载点上进行的任何操作,都只发生在被挂载的目录或文件上,原挂载点的内容被隐藏起来不受影响。
需要注意的是,这个
/test目录里的内容虽然挂载到容器rootfs的可读写层,但是并不会被docker commit 提交。
是因为,容器的镜像操作都是发生在宿主机空间的。由于隔离作用,宿主机并不知道这个绑定挂载的存在。所以在宿主机看来,容器中可读写层的/test目录(/var/lib/docker/aufs/mnt/[可读写层ID]/test)始终是空的。
Docker全景图
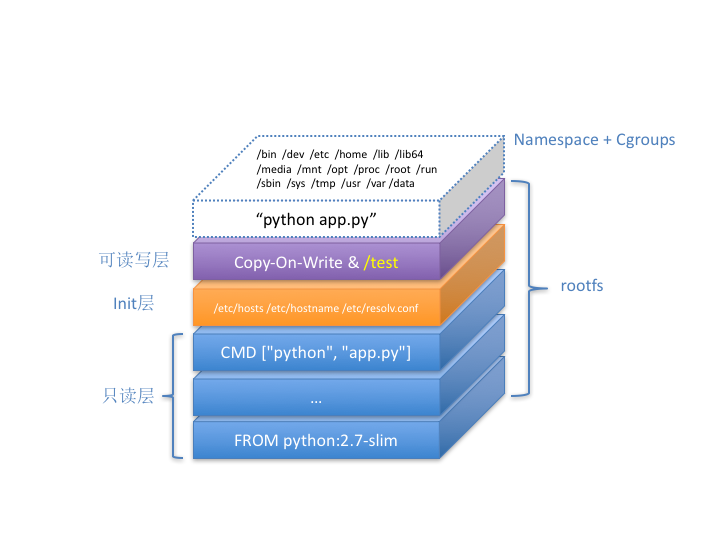
容器进程python app.py,运行在由Linux Namespace和Cgroups构成的隔离环境里;而它运行所需要的各种文件,比如python,app.py,以及整个操作系统文件,则由多个联合挂载在一起的rootfs层提供。
这些rootfs层的最下层,是来自Docker镜像的只读层。
在只读层上,是Docker自己添加的init层,用来存放被临时修改过的/etc/hosts等文件。
而rootfs的最上层是一个可读写层,它以Copy-on-Write的方式存放任何对只读层的修改,容器声明的Volume的挂载点,也出现在这一层。